
Live Migration from AWS DynamoDB to MongoDB Atlas: A Seamless Transition
DynamoDB is a NoSQL key-value database fully managed in the cloud by AWS. Although fast and scalable, its proprietary nature binds your business to AWS. When offering your software to other businesses and integrating with them, this might limit your company’s opportunity to reach more clients. For example, if your potential client’s systems are already operating on Google Cloud Platform or Microsoft Azure you might be required to setup your software on their cloud instead.
MongoDB Atlas as an alternative to DynamoDB
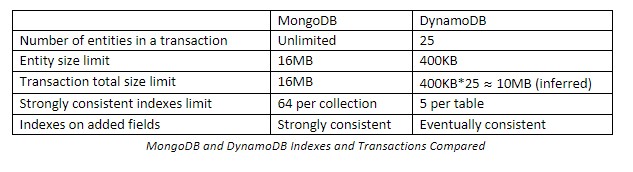
When looking for alternatives to DynamoDB, many might consider MongoDB Atlas. MongoDB is also a NoSQL database, but the fully managed Atlas service is multi-cloud by design so it can be as easily deployed on AWS as on GCP or Azure. Another reason MongoDB might be chosen are the limitations of DynamoDB indexes and transactions, shown in the table below, as well as the fact that fields added after the table creation cannot be index in strongly consistent manner on DynamoDB. This second limitation exists because in DynamoDB the Global Secondary Index needs to be created during table creation and cannot be later changed, which may hinder development of your constantly evolving software.
Migration Approach Goals
For those looking to gain from the flexibility of MongoDB there is fortunately a clear migration path from DynamoDB. For live production systems any downtime or data loss can translate into a loss of income or reputation, so the migration strategy must focus on achieving:
- No downtime, or at least minimal downtime on live production system
- Progressive rollout for small groups of users to verify functionality and performance
- Roll-back possibility to the old solution without losing data created on the new one
The following sections will explore an approach that can achieve this, first examining how data can be mapped and then the process of migration itself.
Data Mapping
Starting with a JSON format comparison – both MongoDB and DynamoDB use JSON to export/import their data, however their data types and schema are not the same. Let us compare DynamoDB JSON to MongoDB Extended JSON v2:
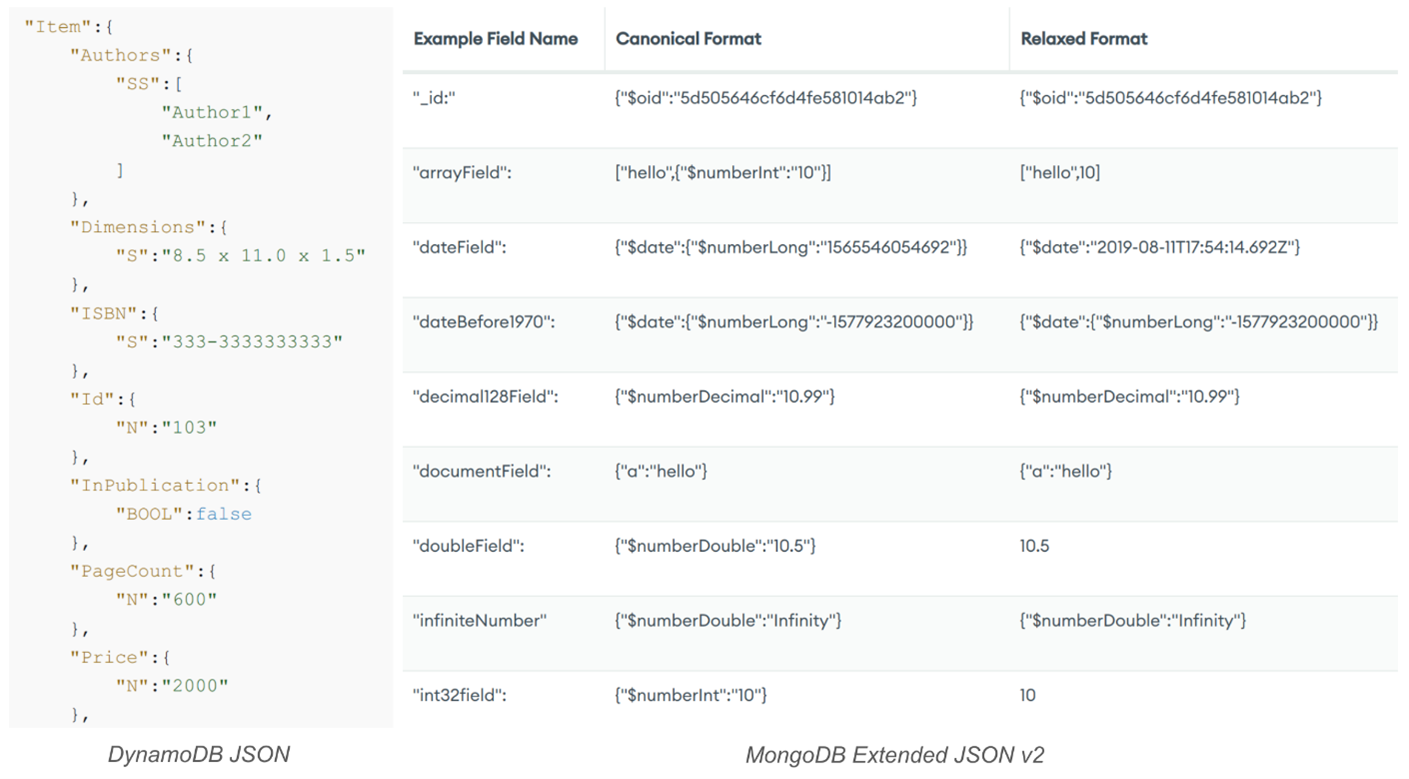
We can see that DynamoDB JSON has types like “N”, “S” or “SS” between field name and value. MongoDB JSON in Canonical Format also has such types, like “$date”, “$numberDouble”, “$numberInt”, they are however different. One way to deal with that would be to write a script to convert the database dump to the MongoDB’s expected format but let us first explore a separate way that does not require writing of a custom code.
An alternative format that we can choose while exporting a DynamoDB table is Amazon Ion. It is still incompatible with MongoDB JSON but can be easily down-converted to type-less JSON as seen below. This down-converted type-less JSON is then compatible with the MongoDB simplified Relaxed Format JSON schema seen in the table above.
Data Types Compatibility
Despite the fact that type information will be lost while executing the conversion mentioned above, the mongoimport tool can automatically detect basic types like string, int, double, array or document. Since DynamoDB does not natively support date-time data type, dates are stored in ISO-8601 UTC formatted strings (e.g. “2022-08-31T12:31:18Z”) due to its lexicographic ordering property. If present, Blobs and Clobs need to be under 16MB limit and will be converted to Base64-encoded string and ASCII-encoded string, respectively.
Migration
The migration will take place in three key phases to achieve the full migration goals
- The Full Load Phase: Taking an initial snapshot copy of the data from DynamoDB to MongoDB
- The Forward Sync Phase: Copying forward any incremental data changes that have occurred in the DynamoDB source since the snapshot used in the Full Load phase was taken
- The Backward Sync Phase: Enabling changes made in MongoDB to be back-populated in to DynamoDB so that the two data sources can run in parallel during the migration proving period
Full Load Phase
In this phase we take a DynamoDB table dump in Ion format and store it on S3. This can be executed from the AWS Management Console. Then we can log on the ECS, access the S3 dump file and execute the simple conversion script available from AWS to down convert Ion to JSON. Finally, we can execute the mongoimport tool with “Relaxed Format” mode to import data to MongoDB.

Forward Sync Phase
While we were performing the full load phase, new data will have been produced on the live original application. To bring our new MongoDB database up to date we start by enabling DynamoDB Streams, which is a Change Data Capture (CDC) for item-level modifications on DynamoDB. Since events in that stream are ordered and deduplicated, it is great for our use case. We can connect this stream to AWS Lambda and write a custom code that will parse the event and upsert (or delete) the documents modified.

Since we do not want to miss any events, the DynamoDB streams should be enabled before the table export from the previous phase, and lambda enabled after the end of import. That will result in some unnecessary events processed, but since upserts are idempotent applying them should have no impact on the data, and we can just ignore empty deletes. Since we will have some backlog of messages to process, we can monitor the ReturnedItemCount metric on CloudWatch to know when we are fully synchronised. We also need to mark entities migrated in this way as ”forward-synced” in MongoDB – we will need that in the next phase.
Backward Sync Phase
In the last phase of the migration we want to send any new data created on the MongoDB database back to the old DynamoDB one. This allows us to keep the old system active while proving out the new one, and enables us to start using the new MongoDB database before shutting down DynamoDB. This ‘backward sync’ can be easily achieved via AWS Database Migration Service, an automated database migration tool that supports MongoDB to DynamoDB migration out-of-the-box. We need to choose the “CDC only” migration type to replicate data changes only and not the whole DB.

To avoid backward-syncing entities that has been forward-synced, thus creating a loop, we can create a DMS filter to skip entities that has been marked as “forward-synced” in the previous phase.
IDs and Indexes
The MongoDB _id entity identifier will be automatically for us generated during the import. DynamoDB’s items are usually identified by Composite Primary Key composed of Hash Key (HK) and Sort Key (SK). There might also be Local Secondary Indexes (LSI) and Global Secondary Indexes (GSI), each having their own HK-SK pair.
For all above HK-SK pairs we need to create a MongoDB index to allow for as efficient querying of entities as before. This will also introduce strong index consistency that GSIs were lacking. Additionally, if the data that our application returns need to be sorted using a different field than the range filtering is done on we can take advantage of MongoDB’s Equality-Sort-Range rule by mapping Hash Key to the Equality part, Sort Key to the Range part, and sorting field to the Sort part for improved performance.
Approach Limitations
The main limitation of this migration approach is due to DynamoDB Streams having a data retention limit of 24 hours. Events older than that might be removed at any moment, which means that we have a maximum of 24 hours to complete the Full Sync Phase before we start the Forward Sync and start consuming changes. To mitigate this, migration can be executed on table-by-table basis, migrating one table at a time before moving to the next one. We can also delay creation of indexes to after migration is done to minimise write time during the procedure.
The final downtime during a switch to the new application will depend on the replication latency of the forward-sync phase. With low, sub-second values we could go for a no downtime migration, but higher ones might require some downtime to allow data to fully propagate to the new instance. A final decision on the approach will depend on what those delays mean for your business.
Summary
In this article we have shown that live migration from DynamoDB to MongoDB is possible using available import/export tools and converters. Minimal or no downtime migration can be achieved using DynamoDB Streams CDC and AWS Lambda, with the Lambda function being the only custom code to be written. We have provided the possibility to fall back to the old application without losing data created on the new one thanks to AWS Database Migration Service. We have also shown how DynamoDB limitations regarding consistent indexes and transactions can be overcome by MongoDB.
Have you migrated from DynamoDB to MongoDB, or are you interested in doing so? Please get in touch at hello@gravity9.com