
Getting Started with MongoDB in .NET: A Step-by-Step Guide
MongoDB is one of the most popular representatives of the NoSQL genre of databases so most developers probably don’t need to be introduced to it. If you’ve heard of NoSQL then you’ve almost certainly heard the MongoDB name too. However, this post won’t be about explaining what this magical data storage type is. I assume that since you’re reading this article you already know that, and if you want to learn more, I’ll refer you to the extensive documentation (https://www.mongodb.com/nosql-explained).
When to start working with MongoDB?
Before you start working with MongoDB, it is worth asking yourself if you really need this Mongo or any other non-relational database type, or if it is not the result of the ubiquitous hype for similar solutions. If you answered “no” to the second question, we can now consider when it is worth using a non-relational database.
- You need fast access to data.
- Time of delivery of the application to production is important to you.
- You assume that the data schema changes frequently during development.
- You need to process large amounts of data, so you expect easy horizontal scaling.
- You are uncertain about the final structure of the data, or part of the data will never be structured.
- You want to build an application based on a map – here I invite you to my article I wrote recently on my blog (https://netsharpdev.com/2021/09/09/geoindexes-in-mongodb/)
- You need distributed transactions on database in the cluster.
If any of the above points match your requirements – you should consider using MongoDB.
How to configure MongoDB in .NET?
Let’s start with the fact that we have several options. We can install MongoDB locally, download the Docker image and run, or use the free option in MongoDB Atlas. I will choose the latter option because it will also allow us to load sample data. Using MongoDB Atlas we also get 2 additional replicas at our disposal, so we can practice sharding or writing from one and reading from the other.
Creating a Database in Atlas
- To create a database, log on tohttps://cloud.mongodb.com/.
- In the selection options, we can create the database on AWS, Azure or Google Cloud.
- After the database is created, select „Connect”.
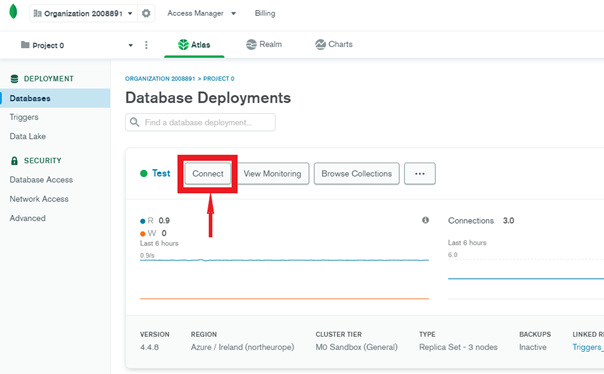
- Add the user who will be used to connect to the database and add his IP address to the access list. (For development purposes, with frequently changing IP addresses, you can allow all addresses to connect to the database – but remember not to allow such access in production!)
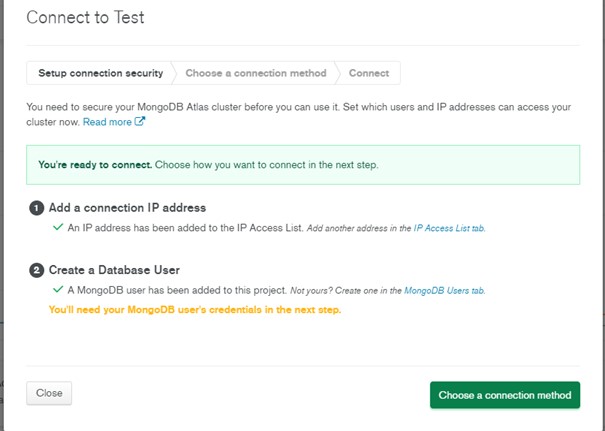
5. The next step is to choose the connection method. Select “Connect your application” and choose the appropriate Driver.
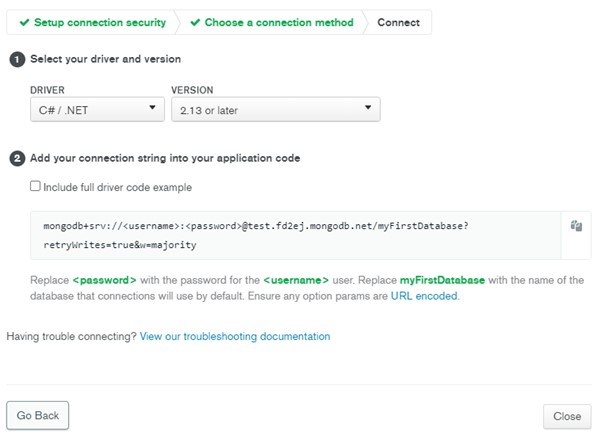
- Copy the connection string and save it somewhere in notepad. It will be useful when we configure the connection in our application.
Connection Configuration
The first question that comes up when using a database in our application is: “Which nuget package to use?”. There are many solutions available in our code market, nevertheless the best approach is to choose MongoDB.Driver. It is the official client, supported by MongoDB. Using it we can be sure that the latest functionalities will be implemented. You can also find EntityFramework adaptations for MongoDB, but I don’t see a single reason to use that. MongoDB as a non-relational, document database is tailored and written perfectly to not use any ORMs. It uses JavaScript to read and write data, so any object-oriented language can be very easily used to adapt JavaScript commands. Let’s go to the configuration.
- Save the connection string you copied earlier in the appsettings.json settings file. Remember to replace <username> and <password> with the correct values.
- in the Startup.cs file, register MongoClient as a singleton.
Singleton in this case is one of the good practices when working with MongoDB. Authorization and authentication are expensive operations so we want to avoid them by creating a single client for the application to minimize these calls. The MongoClient object is safe during multithreaded calls.
See how easy it is! Everything is configured, now we can start using Mongo by injecting the MongoDB client!
Loading Sample Data
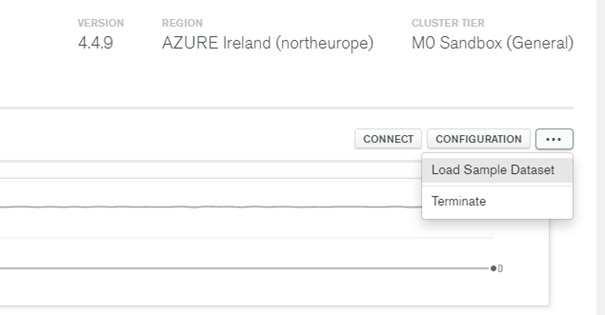
On the right side in the “Overview” tab of our server there is an option Load Sample Dataset. Just click on it and wait for the test data to be loaded into our MongoDB Atlas.
CRUD Operations
Creating basic CRUD operations in MongoDB is simple. You create a repository, use the client, and you’re done. It is important not to create new POCO objects unless there is a clear reason to do so. There is no point in slowing down the data reading process just because of the mapping between POCO and business objects. We can configure the entire mapping using BsonClassMap – this avoids the use of attributes and separates the infrastructure from the application business logic.
I’m going to start by creating a simple class to represent the business object “Restaurant”. I don’t need all the data that is available. I just want to know what restaurants exist, what cuisines they offer, and what city they are located in.
As you can see, my object is completely independent of MongoDB because the “Id” field is expressed as a string. I didn’t use the ObjectId type here at all because I want this one to be encapsulated in the data access part and never go beyond it.
Next, I will create a RestaurantRepository that will contain operations to create a new object, retrieve one or more objects, and update/add a new field in the document.
As you can see, these 4 methods were created in a very simple way. However, executing this code will end up with an explosion titled FormatException ☹. To avoid this we need to configure the mapping! There are two ways – tagging the Restaurant class with attributes or configuring it in the Startup class. We will choose the latter option because, we want to avoid the situation where MongoDb.Driver is used outside the data management layer.
For this purpose, I will create a static method that will be used to configure the different options.
I will put this method in static Configuration class in data access layer. It was created just for the purpose of such configuration.
Is that all there is to it though? Unfortunately no… What we have done here is to tell the mapper to do an automatic mapping. We also want it to take into account that the RestaurantId field in the document is named “restaurant_id”. We could solve this by creating our naming convention and setting it with ConventionRegistry. However, I would like the naming convention in this system to be set as “camelCase”. But about that in a moment.
First, I’d like to discuss what happens next in our BsonClassMap. I’m indicating that the new serializer set up for the Id field converts the ObjectId to a string type. The last line of the above code ignores all document fields that have not been added to the Restaurant class. Without this line, MongoDB.Driver would throw an exception because it could not find these fields in the target class.
Conventions Setup
This is a fairly simple but important operation. In the same static method I just created for configuration, I call the following code snippet.
I am creating an object of ConventionPack type and adding conventions which I would like to set during serialization and deserialization. You can set here, among other things, how the Enum will be serialized – as a text or as a number. We can create any number of such conventions. What is more, the conventions are applied to particular types. In my case, they are applied at the level of the entire namespace.
And that’s it. Our MongoDB is set up and ready to go.
UpdateOne or ReplaceOne?
There was a CreateOrUpdateField method in the repository. You may have asked yourself, “But why? Why not update the entire document?” A valid question, and it would seem that after all, in all ORMs for SQL we do this! With MongoDB, you have to specifically define what field you want to add/remove/change. It is possible to replace a document with a new one thanks to the ReplaceOne method, but this is not recommended for several reasons.
Firstly – it takes more time and resources to replace the entire document. It is simply inefficient.
Secondly – our “Restaurant” class does not have several fields available in the document. ReplaceOne would result in deleting those fields when updating (replacing the document) and the data would disappear forever, while I would like to change only the type of cuisines offered by a given restaurant.
Third – when using the increment operators that are available with UpdateOne, for example, if two concurrent threads perform operations on the same document, both operations will be saved – that is, the incremented number will change twice. In the case of using ReplaceOne, if one thread has changed the document, the change coming from the other thread will overwrite the current state with the data that the thread has.
By using UpdateOne, several services can use the same document model without deleting fields that a particular service does not use. I encourage you to continue exploring the world of MongoDB! I also want to invite you to visit https://university.mongodb.com/ to expand your existing knowledge about MongoDB!