
Retrieval Augmented Generation (RAG) and its Necessity
Large Language Models (LLMs) have taken the world by storm. These AI models can generate human-quality text, translate languages, and write different kinds of creative content with the ease of a changed prompt. They’ve revolutionised communication and content creation. However, LLMs have a fundamental limitation: their knowledge is restricted to the data they were trained on. This can lead to factual errors, outdated information, and even meaningless outputs when prompted on topics outside their training dataset.
This is where Retrieval-Augmented Generation (RAG) steps in. RAG represents a significant leap forward in LLM technology. It bridges the gap between LLMs and the real world by allowing them to access and leverage information from external knowledge sources. Imagine the difference between taking a closed-book exam and having an entire library at your fingertips! RAG empowers LLMs to become more factual, reliable, and adaptable to ever-changing and growing information.
What is Retrieval Augmented Generation?
In May 2020 Meta introduced a framework called Retrieval-Augmented Generation, akin to moving from a closed-book to an open-book examination. This framework, detailed in the paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” fundamentally transformed how LLMs access and utilize information. RAG allows LLMs to build on a specialized body of knowledge to answer questions more accurately.
Typically, LLMs rely solely on the vast array of information they were trained on. This method, while powerful, confines their responses to the scope of their pre-existing knowledge base, limiting their ability to provide up-to-date or highly specialised information. Enter RAG: a system designed to break these constraints by allowing LLMs to consult external data sources, in real time, to answer queries.
RAG is a hybrid AI model that ingeniously combines the capabilities of two distinct systems: a retrieval system and a generative system. The retrieval system is tasked with sourcing relevant information from a vast database, or corpus, effectively sifting through extensive volumes of data to find pieces of content that best match the input query. Meanwhile, the generative system (typically an LLM) takes this retrieved information and uses it to generate coherent, contextually appropriate responses.
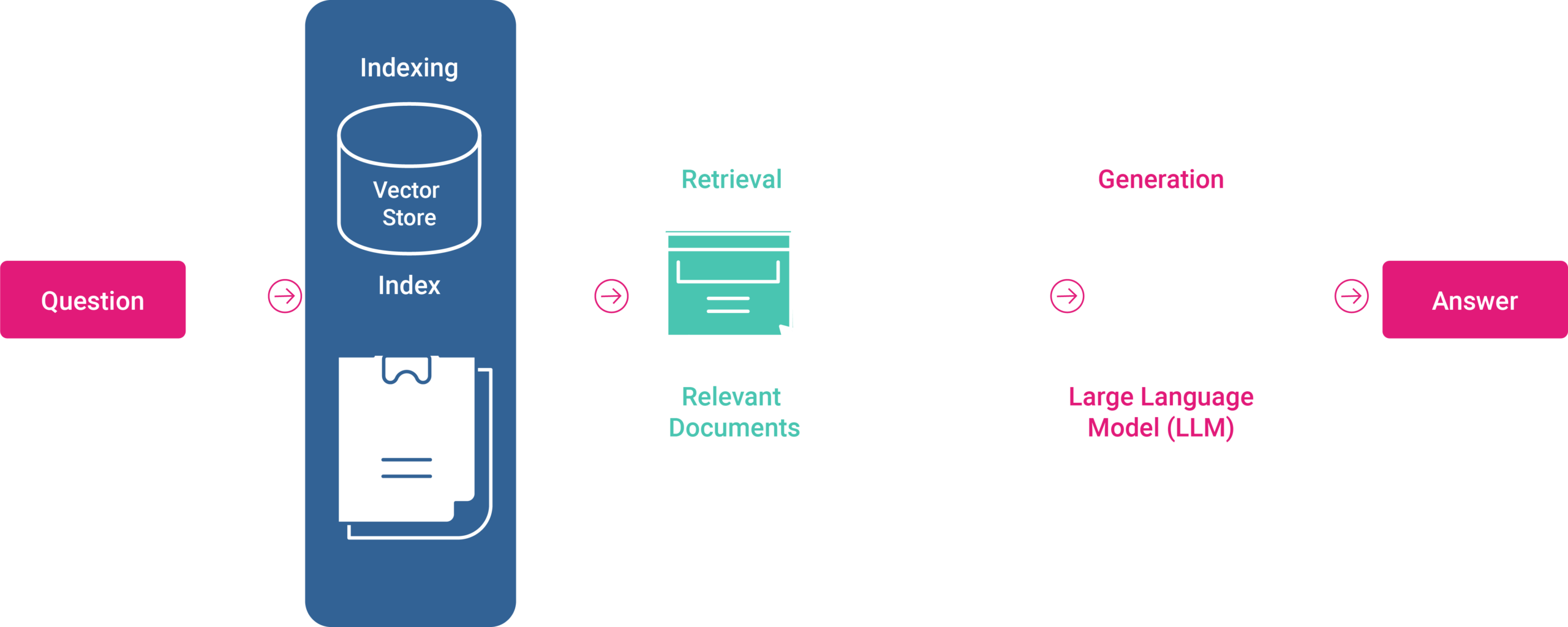
Addressing the Limitations of LLMs
People turn to LLMs for knowledge acquisition, problem-solving, language learning, and mathematical calculations, yet fundamentally, LLMs excel at predicting the next word in a sequence through statistical probabilities. LLMs, despite their impressive generative abilities, suffer from inherent limitations that RAG seeks to overcome:
- Knowledge Cut-off Date: A fundamental challenge with LLMs is their inherent knowledge cut-off date, since these models are trained on datasets that are compiled up to a certain point in time. Their knowledge is effectively frozen at the moment their training concludes. This limitation becomes particularly evident in our rapidly changing world, where new information, discoveries, and events occur daily. Traditional LLMs, without access to real-time updates, can quickly become outdated, limiting their applicability in scenarios that demand the latest information. RAG circumvents this issue by accessing the most current data, ensuring responses reflect the latest developments.
- Hallucination Problems: Another critical issue that RAG addresses is the hallucination problem, where LLMs generate plausible sounding, but entirely fabricated or inaccurate, pieces of information. This is often a result of the model’s attempt to fill in gaps in its knowledge base or when it extrapolates beyond the scope of its training data. Such inaccuracies can significantly undermine the credibility and reliability of the AI system, especially in critical applications such as medical advice, financial analysis, or news dissemination. By leveraging external data sources, RAG models significantly reduce such hallucinations, grounding their outputs in verified information.
The Benefits of using RAG
RAG offers a powerful toolkit to enhance language models in significant ways:
- Cost-effective Alternative for Fine-tuning: Fine-tuning LLMs to keep them updated with the latest information is resource-intensive, requiring substantial computational power and data. RAG addresses this by dynamically integrating current information from external databases, reducing the need for frequent and costly retraining cycles. This approach not only saves resources but also ensures that the model remains up to date without the continuous investment associated with fine-tuning methods.
- Credible and Accurate Responses: RAG enhances the credibility and accuracy of AI-generated responses by directly leveraging information from trusted sources. This significantly reduces the generation of factually incorrect or misleading content, a common issue with standalone LLMs. By grounding responses in real-time, verified data, RAG ensures that the information it provides is both trustworthy and relevant.
- Domain-specific Information: The ability to access targeted databases or repositories allows RAG to deliver highly specialized and domain-specific information. This is particularly beneficial in fields requiring expert knowledge, where accuracy and detail are paramount. RAG’s dynamic retrieval capability means that even niche queries can be addressed with a high degree of precision, tapping into the latest research or data relevant to the specific domain.
- Enhanced Transparency: By sourcing information from identifiable databases and documents, RAG models offer a level of transparency uncommon in LLMs, where the origin of generated content is often opaque. Using RAG, users can trace the origin of the information provided in responses, understanding the basis of the model’s outputs. This transparency not only builds trust but also allows for the verification of facts, contributing to more informed and confident decision-making.
- Context-aware Generation: With the ability to pull in relevant external information on the fly, RAG models excel at understanding and adapting to the context of a conversation or query. This context awareness ensures that responses are not only accurate but also appropriately tailored to the specific situation or need. The result is a more nuanced, intelligent interaction that mirrors human-like understanding and adaptability.
- Scalability: The architecture of RAG is inherently scalable, capable of integrating more information sources as they become available. This ensures that the model’s capabilities and knowledge base can grow over time, without the need for complete redesigns or extensive retraining. As a result, RAG can continuously evolve, adapting to new information landscapes and expanding its utility across different contexts.
- Industry and Domain Agnosticism: RAG’s flexible architecture allows it to be applied across various industries and domains, from healthcare to law to entertainment or education, making it a versatile tool in the AI toolkit.
RAG Architecture
Within RAG architecture, there are various stages to consider. This section will explore a basic implementation, with a more advanced version examined in a future article.
Basic RAG architecture is designed around a straightforward yet powerful process that enhances the capabilities of LLMs through the retrieval of external information.
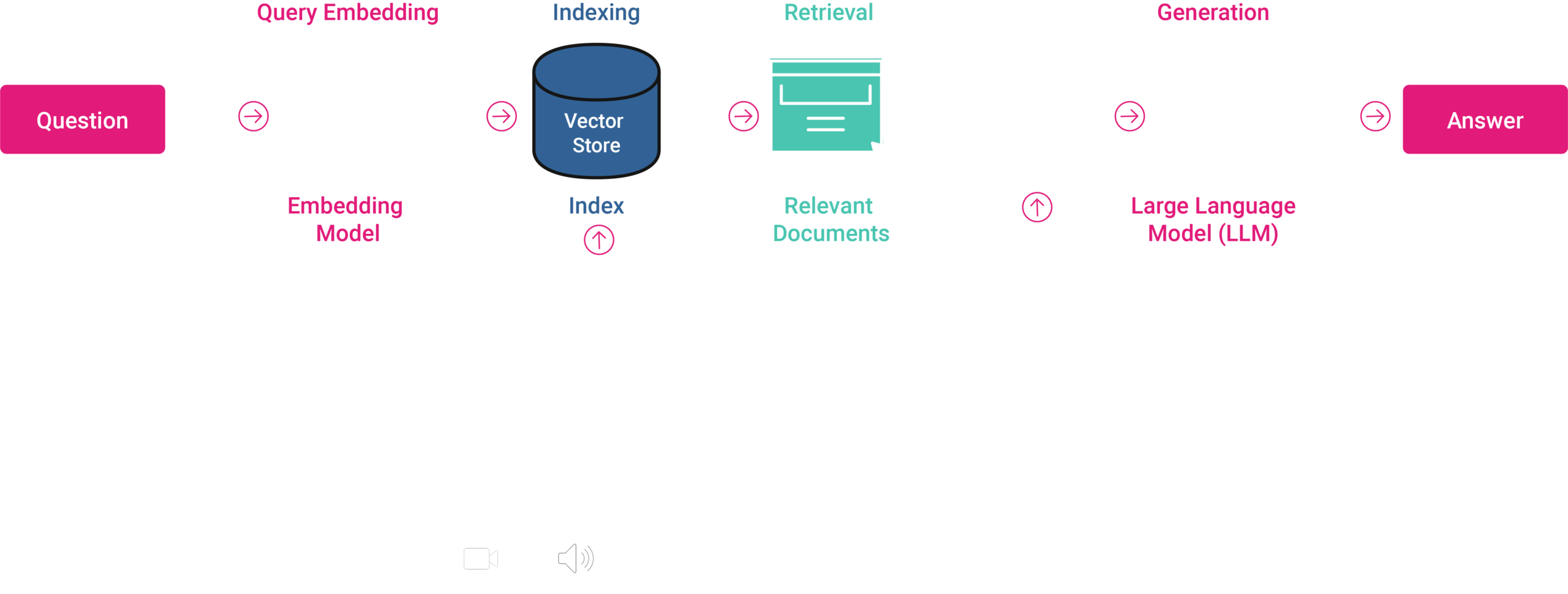
This architecture can be broken down into a series of essential steps:
- Data Extraction, Embedding and Indexing: This foundational step involves gathering data from a diverse array of sources (e.g. databases, cloud storage, APIs, web pages, data lakes, data warehouses). This data then undergoes an indexing process, which includes chunking (breaking down the data into manageable pieces), embedding (creating dense vector representations of each chunk for semantic understanding), and preparing it for storage in suitable databases (like Graph DB, Relational DB, or Vector databases). This indexed data repository is crucial for rapid and relevant data retrieval.
- Query Embedding: When a user query is received, it is first transformed into an embedded form. This embedding process converts the query into a vector representation, making it compatible with the indexed data and ensuring that the retrieval process can efficiently identify relevant information.
- Retrieval: With the query now in an embedded form, the system searches through the indexed data to find and retrieve information chunks that are relevant to the user’s query. This step leverages the pre-processed, indexed data to ensure that the retrieval is both fast and accurate.
- Generation: The final step passes the retrieved data, alongside the original user query, to a large language model. The LLM then synthesises a response, integrating the retrieved information with its generative capabilities. This allows the model to produce answers that are not only based on its pre-trained knowledge but also enriched with the latest, specific information related to the query.
This basic architecture encapsulates the essence of RAG’s approach: augmenting the capabilities of LLMs by providing them with access to a broad spectrum of external information. By doing so, RAG significantly enhances the relevance, accuracy, and contextual awareness of the responses generated, making it a powerful tool for a wide range of applications.
From Basics to Beyond: Bridging into Advanced RAG Architecture
As we’ve explored the foundational principles and components of the basic Retrieval-Augmented Generation (RAG) architecture, it’s clear how this approach significantly enhances the capabilities of Large Language Models (LLMs) by integrating real-time, external data retrieval. Through a structured process of data extraction, indexing, query embedding, retrieval, and generation, basic RAG architectures offer a dynamic and efficient method for producing more accurate, relevant, and contextually enriched responses.
This exploration sets the stage for delving deeper into the complex world of advanced RAG systems, where the integration of sophisticated algorithms and techniques further refines and optimises the retrieval and generation process. In the next article, we will uncover the complexity of Advanced RAG architectures, offering insights into the cutting-edge developments that are pushing the boundaries of what AI can achieve.
Stay tuned to explore how advanced techniques like multi-query decomposition, semantic routing, specialized indexing, and enhanced generation algorithms are redefining the landscape of large language models.