
Our client for this project is a globally successful investment bank and financial services provider, active in over 50 countries.
We created this proof-of-concept for them to demonstrate the approach required to migrate their applications from the current Oracle relational databases they’re built on currently to a MongoDB system.
The project covers three main areas:
- The approach to data modelling
- Building effective data queries
- Establishing a high development velocity for the migration.
To offer a high-level overview of the approach, challenges and benefits to come from such a migration we created two Java Spring Boot applications. In both cases the application service is designed to process payment messages using the widely adopted industry standard ISO 20022 financial messaging format.
The first application uses Oracle, Hibernate and Spring Data as a repository layer. This represents the present state of the client’s applications – the status quo – which their developers will recognise as a simplified example of their own current working environment. This creates a baseline to show how the migration to MongoDB would be possible from their ‘starting’ position.
The second application alters the first to use MongoDB instead and represents the “after” – the post migration example.
The Solution (Part 1)
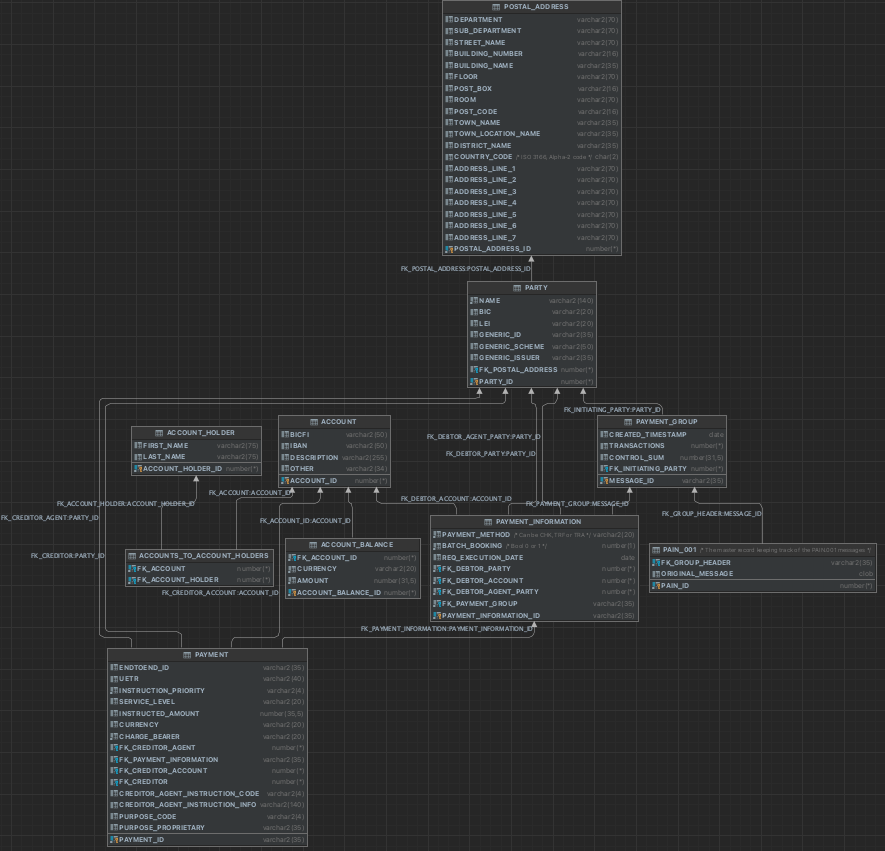
Beginning with the first of the two applications, we analyzed the ISO 20022 documentation provided by the client and created a relational data model to mimic how the client processes payments.
This can be seen in the image below:
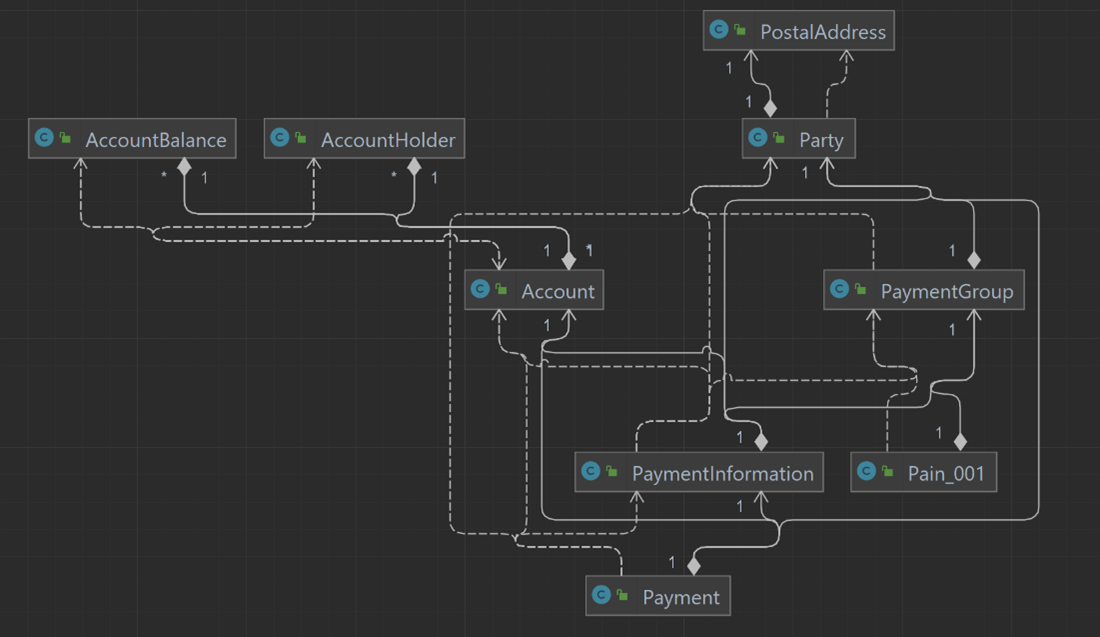
Next, a Java Persistence API (JPA) model including tables, sequences and JPA Entities was mapped for use in Spring Boot:
A REST API was then created to allow the service to consume Pain_001 messages (a payments initiation message by ISO 20022 that depicts a credit transfer message in XML format). Endpoints to retrieve data were created on an API level. A requirement of the application was to retrieve all payment information grouped by a given date and then return the sum of the payments by currency.
Here’s an example repository implementation that provides that data:
Finally, the Oracle based application was deployed in Microsoft Azure. An Azure pipeline was created to build, test and deploy the service as new changes were committed.
This concluded the creation of the first (Oracle based) application: providing a working example of the status quo of the clients working environment that their developers recognise and are familiar with using Oracle, Hibernate and Spring Data.
The Solution (Part 2)
The next step is to duplicate the functionality of the first application, but based upon MongoDB rather than Oracle.
From an API point of view, there are no differences. The changes will affect only the data model and repository layer. To create the new repository layer we used Spring Data in order to demonstrate that the same queries used by Oracle and Hibernate could also be applied to MongoDB.
The greatest changes took place in the data model. Typically, in SQL databases, entities exist in different tables to avoid duplication issues. That approach has a benefit (reduced storage space usage) but also a negative (it requires joins when fetching data, which can slow queries down). In the past, storage was expensive so optimizing for small data storage made sense, but in modern systems storage is cheap and performance is the key driver of success, which is part of the reason that Document databases like MongoDB are a so popular for modern architectures.
MongoDB promotes embedding as a relationship model – storing data that’s often queried together in a single document – which allows for meaningful speed increases when querying.
A further difference between MongoDB and Oracle is how Oracle relies on schemas where MongoDB does not. Schemas are blueprints used to specify what type of data each table supports. This approach is rigid and rejects any new inserts if the data provided does not match the type specified in the schema. MongoDB is schema-less by default and can accept any type of data without the need for a schema blueprint. This allows for faster development cycles as any change to the type of data used will be accepted.
We now reach a key topic in this proof of concept; how to move from a SQL schema driven data structure to a schema-less one (NoSQL). The MongoDB Relational Migrator tool provides an effective mechanism for modelling and migrating data according to the best practices we will outline in this section.
The image below shows collections residing in MongoDB, which are the equivalent to tables in relational databases. Creating collections from tables is not a straightforward process as the data has to be remodelled from a relational form into document form.
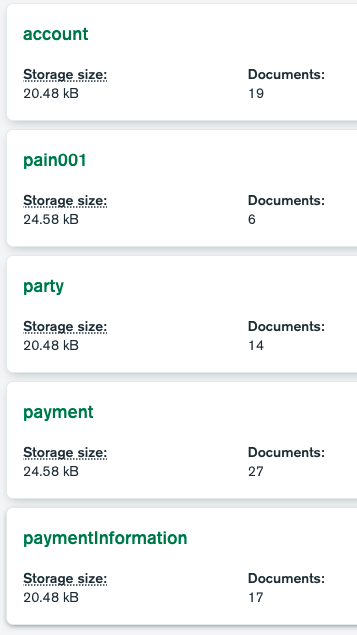
Screenshot: MongoDB Collections
There are several techniques used to model data on NoSQL databases: Full Embedding, Partial Embedding and New Collections. Each refers to how we might distribute data within the database.
In an SQL database we would distribute data across different tables, however this is inefficient in MongoDB, so we prefer to use one single embedded document with all the data contained in it.
Full Embedding is an effective way to arrange data together, improving the performance of queries.
Referring to our SQL data structure (the first image in this document under the “Solution” heading), there is a table named “POSTAL_ADDRESS” that is only used by the entity “Party”. We analysed this and found that – most of the time – when “Party” is queried, we also want to query the postal address relevant to the party.
For this reason, the postal address was embedded inside the Party entity as follows:
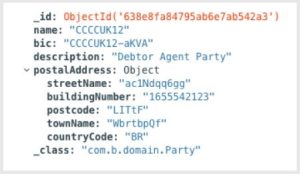
Screenshot: Full Embedding Example
Partial Embedding is akin to a foreign key in a SQL database.
In this case we don’t want to embed the entire document, only the “_id”. Below you can see how the “Account” collection is modelled in MongoDB:
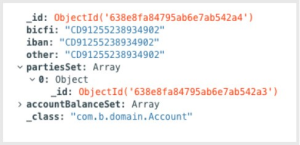
Screenshot: Partial Embedding Example
As you can see, we’ve only saved the “_id” of the party.
This decision was made as “Party” has its own collection as required by the application. If we had full embedding of the party into the “Account” collection, we’d be forced to update multiple documents within MongoDB in case we wanted to (e.g.) update the postal address of the party.
Failing to update all documents that are used by the party would produce inconsistent data.
To prevent this issue, only the “_id” was copied, freeing the application from having to update multiple documents in the case that the party needs to be updated.
A New Collection can be a more simplistic approach: One table from an SQL database – or new data – becomes a new collection in MongoDB. In this case there is no embedding.
This can be seen illustrated within Account, Pain001, Party, Payment and Payment Information.
Once the data was in MongoDB, we showed our client how to query data using the MongoDB connector (for BI and SQL scripts). This is useful as MongoDB operates on MQL, not SQL, which can present new users with a knowledge gap. The MongoDB Connector comes to the rescue here by scanning the MongoDB database and producing an SQL database that can then be explored using regular SQL. It allows users with SQL experience to extract what they need from a MongoDB database without needing to first learn MQL.
Summary
In this project we were able to successfully demonstrate how to migrate an application based on Oracle to MongoDB in a financial services environment, including how to model data within MongoDB and how to query it using Java and MongoDB Compass.
We began with a baseline application built on Oracle and deployed in Azure to check our understanding of the clients’ current system. From there we duplicated this functionality upon a MongoDB database. The data was migrated (using MongoDB Relational Migrator) and remodelled in MongoDB using Full Embedding, Partial Embedding and new Collections depending on what was most suitable. This straightforward but robust process can be used to help you be self-sufficient in migrating applications from Oracle to MongoDB.
Have you migrated from Oracle to MongoDB, or are you interested in doing so? Please get in touch at hello@gravity9.com