
Supermarket Chain Transformation Acceleration Case Study
09 Dec 2022 | Eric Allen
This project was for a UK supermarket chain that had the goal to improve their ability to offer dynamic pricing and targeted promotions to their customers. As a foundational step, they wished to modernize their legacy pricing systems to increase overall performance, ensure better maintainability and enable easier development of new features. They decided to switch their legacy data source to MongoDB Atlas, forming a new team responsible for domain migration and developing new systems. The members of this new team required help to gain skills and knowledge connected to the new modern technology stack. gravity9 proposed a project approach of laying the foundations for the new system while working in parallel to upskill the client team’s so they could continue the work themselves after our engagement.
Legacy data from the old system was held on Kafka topics, and this data was the starting point for the new system. The old data would be transformed and have some business logic applied to bring it into a format that supports new use cases. As a first step, our client wanted to maintain data ingested from the legacy topics in exactly the same form as they were present on the topic for audit and replay purposes. These records were only enriched with some static metadata like ingest timestamps and statuses and stored in a dedicated MongoDB ‘ingest’ collection. A second step in the process was to extract the data from the ingest collection, conduct some transformations and store the transformed data in the new data format collections. The most challenging part of the data enrichment was that there were cases where transformed data was dependent on a few ingest collections.
The most important part of our engagement from our client’s perspective was the knowledge-sharing aspect. By introducing our architectural proposal and walking the team through the decision process in detail, we helped them understand the ideas and how they can build on top of these foundations in their future projects.
After finishing the simplest flow, we had to deal with more complex cases to prove the architectural approach would cover all the business needs that the client’s team will need to implement. The combination of these two flows acted as a foundation for developers to build every other process throughout the whole migration. In this more complex case, we had some data dependencies between a few collections and some atomic operations on the model. Using Kafka topics as our data sources we could not easily guarantee the order of the records between different topics. The client agreed that eventual consistency of the data is enough for their use cases, so when we did not have all the data we needed for the transformations at a certain point of time we introduced some placeholders which were filled after the data arrived later. All the logic was implemented using Atlas triggers, and in the cases where we had to atomically modify other collections based on our data we used transactions in our trigger code.
The Solution
gravity9 started with implementing one simple flow where the goal was to consume a single Kafka topic with legacy records, store them in MongoDB legacy collection, and finally perform mapping and store mapped data in new collections. We used Kafka Connect Connectors to ingest the data, and static metadata fields were added by built-in connector transformations. To avoid hosting and maintaining applications which would transform legacy data to the new formats, we used Atlas triggers to perform the mapping logic.
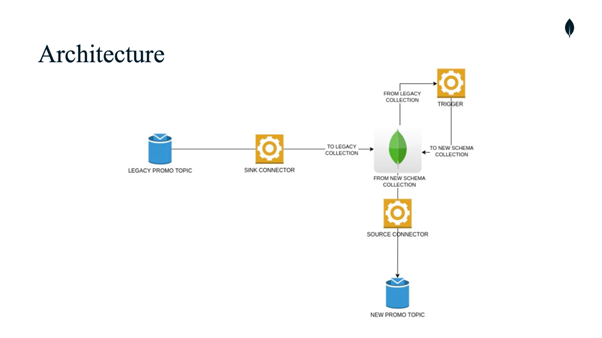
The triggers we used were hosted on the MongoDB Atlas environment. Those triggers could be added to the cluster simply using the UI interface in Atlas, but we preferred to have more control over trigger code, versioning and ability to automate testing. Trigger functions were held in code monorepository and deployed using pipelines. After a successful code review and code merge, a new version was uploaded to Atlas using realm-cli. Unit testing for functions was really easy, as we could mock the data and test functions by simply calling them in our unit tests.
In our engagement we heavily focused on testing our solutions and we decided that unit tests were not enough as we wanted to e2e test the whole flow, starting from Kafka topic and ending in result collection in MongoDB. Triggers are Atlas-based features and we could not test those by using Docker image of MongoDB instance (our unit test approach). We decided to use an Atlas cluster dedicated for testing, and introduce additional mechanisms in our pipelines and e2e test to prepare the necessary infrastructure before running the test suite and then tear it down after conducting the tests. Before running the tests, we created a uniquely named database dedicated for that test run, created the collections and deployed our trigger. After finishing the tests we deleted this dedicated database and triggers. Database uniqueness was very important for the whole concept to work, taking into consideration that there may be a few pipelines running in parallel or that a few developers may want to run their e2e tests at the same time.
We introduced a few working practices that would help us to transfer as much knowledge as possible to the client team. Firstly, we scheduled daily handover sessions from each of the gravity9 developers where we would go over the code and solutions that we applied on that given day. These were detailed and included deeper questions from the client as well. The sessions were recorded and organized in Confluence so that it was easy for the client to refer to them even after the engagement was over, serving as an audio-visual documentation. Additionally, we would also demo any completed features and request for comments from developers. Finally, we also held weekly sessions with key stakeholders from the client’s side where we demoed the suggested solutions and showed how they worked in practice. Since those were targeted at a wider audience, they were less technical and more focused on how MongoDB and Atlas can be leveraged to accomplish specific tasks.
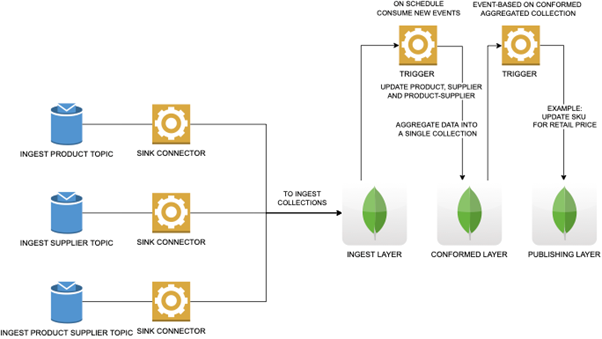
After the foundations were laid for development of the first flow, we began working on a more advanced process with the flexibility and extensibility needed for future solutions. This time around our goal was to accomplish the following:
- Ingest data from dedicated Kafka topics
- Save data to MongoDB collections as-is
- Transform data into an end-model
- Save transformed data to a dedicated “ready to use” collection
Once again, we used the Kafka Connector (sink) to easily satisfy the first step. We prepared a “landing zone” collection where data from our topics would be saved. Next, we set up a scheduled Trigger to transform the data from the Kafka model into a dedicated model that the customer requested, merging multiple documents into a single conformed collection. At this stage we also performed change detection logic so that only the latest version of the documents was stored. All historic data remained in the ingest layer and could be archived to preserve space while maintaining auditability. Additionally, we chose the scheduled version of the Trigger because the customer wanted to have maximum control over how the process runs. Now, by manipulating a single value in a separate collection, the client has control over whether the process should run or not.
The Result
The project was a short one, clocking in at just over a month, but despite the short timeline we were able to focus on areas that were key to the client and deliver in a cost-effective manner.
Firstly, we were able to transfer our knowledge to the team. By taking a step-by-step approach we could explain every decision we made along the way and any questions or doubts were answered. Technical details were clearly communicated while all members of the client team reported being confident in making changes and extending the solution. The client team has gained hands-on experience with MongoDB and Atlas, including more advanced features like per-cluster setup, different types of Triggers, Realm Apps and Kafka Connectors. We finished the engagement with our client feeling well equipped for the future.
Secondly, we were able to deliver a robust process and a solid technical foundation. The final solution included two data flows between related systems comprised of a few core elements:
- An integration with Kafka, including sink and source connectors
- A well designed data model which was mainly done by the client team with our guidance
- A fully fledged database setup in MongoDB, deployed on the Atlas cloud
- A series of Atlas Triggers (both scheduled and change stream-based) with custom data transformations
- Two custom scripts to easily deploy any future changes to this infrastructure
- A testing setup for both integration and unit tests making sure they can be run with client’s current CI/CD pipeline
Finally, one of the objectives of the project was to prepare a template process that could be replicated in other parts of the system. By using extensible and flexible components (like Kafka connectors or Atlas Triggers) we were able to deliver a solution that satisfies this condition. Any future implementation can take either the full template or its specific parts, depending on their needs. The parts themselves can be also freely customized to suit specific use cases. Moreover, the client’s team is now ready to spread the knowledge to other members of the company and pair the solution with expert knowledge.
Visit our Insights page for more case study examples.